Migration of service without downtime: The journey from fulfilment service to fs-neo
Migrating a core service with zero downtime sounds bold—until you do it. We rebuilt our legacy system into something modular, scalable, and future-ready. Here's how DDD, SpringBoot, Istio, and Redis powered one of our most ambitious backend transformations.
Ever run into legacy issues in a codebase? The struggle of trying to integrate a new tech stack into an outdated framework, or simply dealing with a codebase that’s become a chaotic junkyard, is all too familiar. This isn’t a new challenge—and our story is all about overcoming it. In our recent project, we transformed one of our central backend service called as fulfilment service into a re-engineered solution called fs-neo. We didn't just upgrade; we completely rewrote our service architecture and seamlessly migrated all our clients to the new system, all without any downtime. Below, we delve into the motivations behind this bold move, the innovative strategies we deployed, and the remarkable impact this migration has had on our operations.
The Challenge: Why Migrate?
First let’s discuss more in detail about the exact challenges which motivated us to go forward with the migration
Outdated Technology Stack
- From Vertx to SpringBoot: Our previous service was built on Vertx, which, while efficient in handling asynchronous operations, began to show its limitations. Specifically, when it came to integrating with modern asynchronous systems such as Kafka, Vertx’s support was not robust enough. We needed a framework that could better accommodate our growing needs—enter SpringBoot, renowned for its scalability, modularity, and rich ecosystem.
Logging and Debugging Challenges
- Traceability Issues: Our legacy logs were difficult to parse, making debugging a complex and time-consuming task. With the introduction of Trace IDs, we could now track requests end-to-end, significantly enhancing our ability to diagnose issues quickly.
- Transition to JSON-based Logs: Moving from unstructured logs to JSON-based logging not only standardised our logging format but also made it easier to integrate with log analysis tools, paving the way for more effective monitoring and debugging.
Code Quality and Maintainability
- Unstructured and Anti-Pattern Laden Code: The old codebase suffered from unstructured development practices, leading to several anti-patterns. This made it increasingly difficult to introduce new business capabilities or scale the system effectively. The migration allowed us to refactor our code, adopting modern architectural principles to create a more maintainable, scalable, and developer-friendly codebase.
Asynchronous System Integration
- Kafka Integration: Integrating Kafka in our legacy system built on Vertx was a significant challenge. Vertx lacked native support for Kafka, forcing us to implement complex workarounds that made managing real-time data streams cumbersome. With our migration to SpringBoot, native Kafka integration is now fully supported, streamlining asynchronous operations and ensuring efficient, reliable real-time data processing and event streaming.
The Strategy: How We Executed the Migration
Achieving a seamless, zero-downtime migration required careful planning, strategic execution, and a deep understanding of our existing systems. Here’s an in-depth look at our approach:
1. Code Restructuring with Domain-Driven Design (DDD)
Remember we discussed the pain points of code quality and maintainability. To tackle this, we wrote the new codebase using a design pattern called Domain-Driven Design (DDD), which is renowned for its focus on aligning the software design with complex business needs. By embracing DDD, we achieved the following:
- Defining Bounded Contexts:We began by analyzing our existing codebase to identify distinct business domains. By applying DDD, we isolated different parts of the application, ensuring that each module had a clear responsibility.
- Enhanced Modularity:With a modular structure in place, teams could work on specific domains independently. This separation of concerns improved maintainability and allowed us to scale different parts of the system as needed.
- Improved Testing and Debugging:A well-structured codebase meant that unit testing became more straightforward, leading to faster identification of bugs and more reliable code deployments.
A Bit More on How We Use DDD to Make Our Code More Testable
To further leverage the benefits of DDD, we bifurcated the entire service into the following layers:
- Application: This layer handles the orchestration of operations. For example, in the context of a digital transaction service, we might have:
- customers:
getActiveCustomersAppActiongetCustomerAppAction- ...and more as needed.
- customers:
- Controller: This layer manages incoming requests and responses, ensuring that they are routed to the appropriate application services.
- Domain: This is the core business logic layer where all the important business rules reside.
- Repository: This layer is responsible for data persistence and retrieval. For instance, for customers:
- customers:
listCustomersRepoAction
- customers:
- External: This handles interactions with third-party services and integrations.
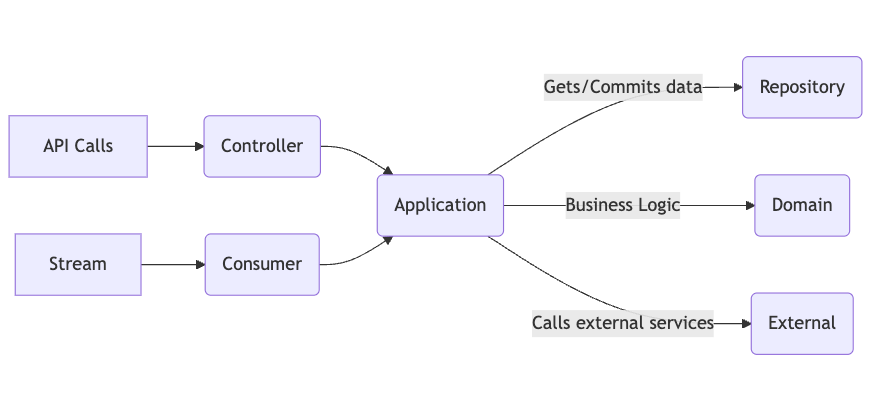
Within each of these modules, we further subdivided the code according to the specific domains identified in our applications. For example, in a digital transaction service, the key domains might include:
- Customers
- Transactions
- Wallets
Per module and per domain, we define specific actions. This clear bifurcation and high modularity allow us to write tests for each application action independently, with the ability to easily mock any required component (such as the repository). This modular approach not only simplifies testing but also enhances the overall maintainability and scalability of the system.
You can read more about this amazing design pattern here → http://medium.com/raa-labs/part-1-domain-driven-design-like-a-pro-f9e78d081f10
2. API Bifurcation: Streamlining Client Interactions
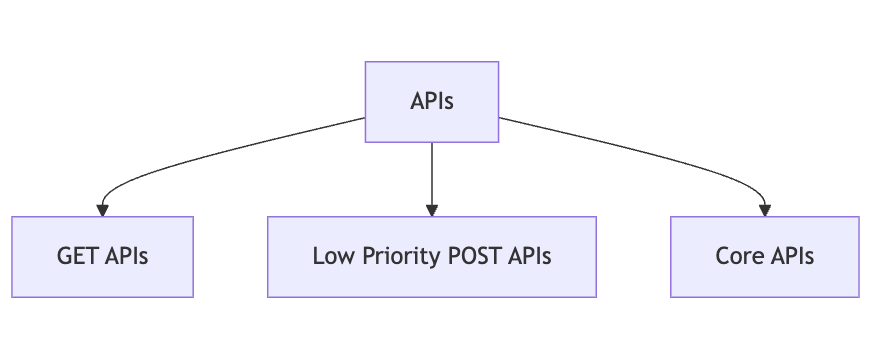
- Segmentation of APIs: We categorized our APIs into three primary groups:
- GET APIs: These endpoints handle read operations and were optimized for performance to ensure quick data retrieval.
- Low Priority POST APIs: Operations that are designed to handle data mutations and non-critical operations rather than managing essential transactions or business logic.
- Core APIs: These endpoints manage critical transactions and business logic. They were given priority in performance tuning and resource allocation.
- Rationale Behind the Approach: This separation not only helped in better managing the traffic but also allowed us to monitor and optimize each category independently. Clients could interact with the system with minimal latency, and any issues could be isolated quickly to the specific API group.
3. Advanced Routing Mechanisms with Istio
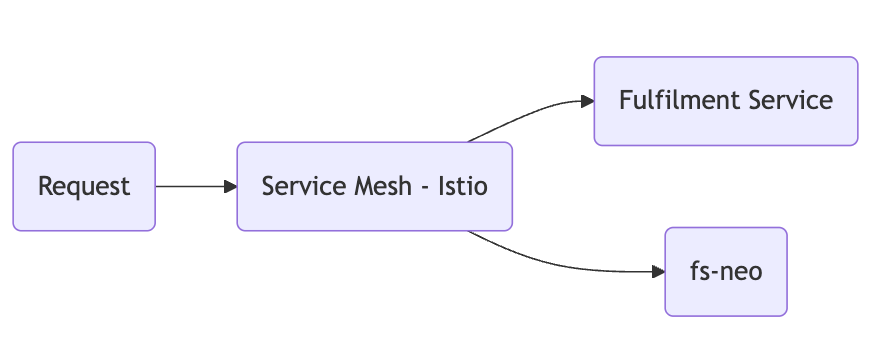
- Uniform Request/Response Models:A key enabler for our seamless transition was maintaining identical request and response models between the legacy Fulfilment Service and fs-neo. This consistency meant that client interactions remained unaffected, allowing us to redirect traffic without requiring any modifications on the client side.
- Partial Routing at the Istio Level: Istio’s robust service mesh capabilities enabled us to direct portions of the traffic to the new fs-neo service. The key here was to ensure that the request and response bodies remained identical across both services, which allowed for a gradual shift of traffic:
- Phased Traffic Migration: Starting with a small percentage (e.g., 10%), we incrementally increased the traffic to 50%, and eventually, 100% of the traffic was routed to the new service. This phased approach ensured that any issues could be identified and rectified without impacting the entire system.
- Parameter-Based Routing Using Redis: In addition to Istio-based routing, we implemented a Redis-backed routing strategy. By tagging requests with specific parameters (such as vendor tour parameters), we could dynamically route traffic to either the legacy or the new cluster. This dual approach provided flexibility and enhanced control over the migration process.
- Controlling the Routing via Redis:
- For each combination of parameters (for instance, vendor and tour), we store a key in Redis—such as
fs-neo:Acme:Summer2025. This key acts as a switch: if its value is set to enabled (or true), it indicates that any API call with these parameters should be directed to fs-neo.
- For each combination of parameters (for instance, vendor and tour), we store a key in Redis—such as
- Client-Side Logic for Header Injection:
- When a client is about to make an API call, the system checks Redis for the corresponding key (e.g.,
fs-neo:Acme:Summer2025). If the key's value isenabled, the client adds an extra header (for example,X-Target-Service: fs-neo) to the API request
- When a client is about to make an API call, the system checks Redis for the corresponding key (e.g.,
- Controlling the Routing via Redis:
curl -H "X-Target-Service: fs-neo" "<http://fulfilment-host/resource>"- Istio Routing Based on the Header:
- Istio is configured to inspect incoming requests for this header. When it detects the header X-Target-Service with the value fs-neo, it routes the request to the new fs-neo service. If the header is not present, or if the key in Redis is not set to enabled, the request defaults to the legacy Fulfilment Service.
4. Handling Legacy and New Systems Simultaneously
- Shadowing and Parallel Running: For a period, both the legacy and new systems were run in parallel. This allowed us to compare outputs and performance metrics in real time. Any discrepancies were addressed promptly, ensuring that the final migration was seamless.
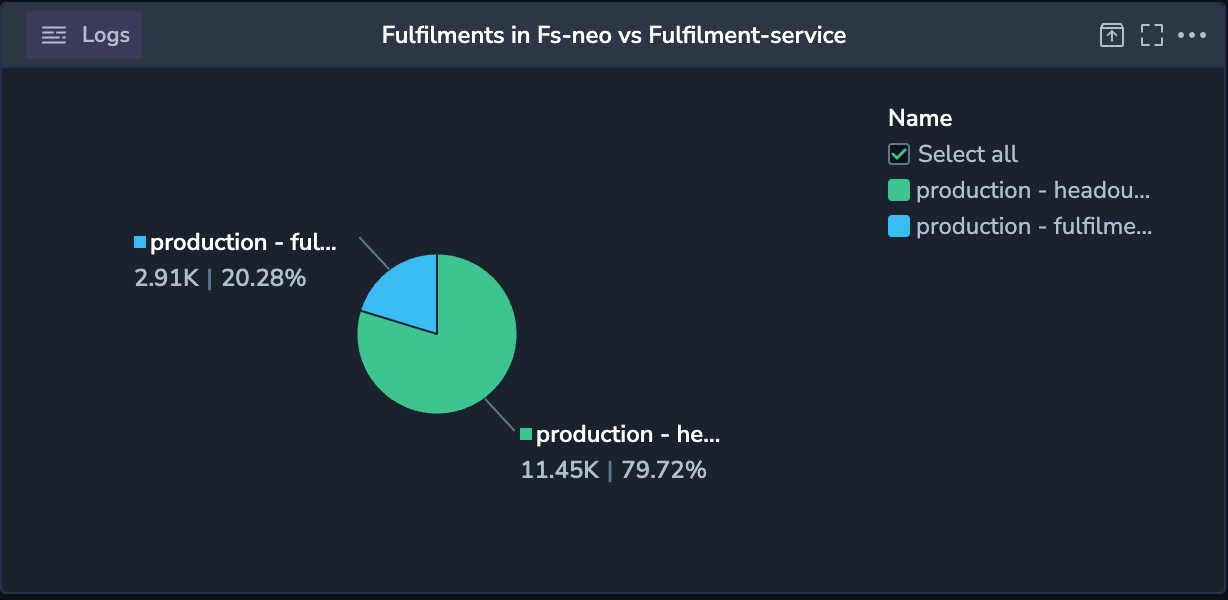
- Real-Time Monitoring and Analytics: Leveraging modern monitoring tools, we set up dashboards to track the performance of both systems. Key metrics such as API latency, error rates, and system load were monitored continuously, enabling proactive issue resolution. Here is one example of a metric in a dashboard we built. This widget denotes the requests to fs-neo vs fulfilment-service
The Impact: What Changed Post-Migration
The migration to fs-neo has had a transformative impact on our operations. Here’s a closer look at the benefits we’ve observed:
Performance Improvements
- Faster API Responses:A key objective of migrating to fs-neo was to enhance overall system performance. By leveraging SpringBoot’s native support for asynchronous operations and restructuring our code, we significantly reduced latencies across multiple APIs. For instance, on the critical
update-pricing (POST)endpoint:- Average Latency dropped from roughly 16.5 ms to 10.2 ms
- P95 Latency went from 24.9 ms down to 14 ms
- P99 Latency decreased from 64.5 ms to 28.9 ms
- These improvements reflect a more efficient system that handles both typical and worst-case scenarios more gracefully. Across the board, most of our APIs saw similar gains in P95 and P99 performance metrics, confirming that our architectural changes and technology choices have directly translated into faster response times and a better user experience.
- Enhanced Kafka Integration: With SpringBoot’s native support and our improved asynchronous handling, our system now processes Kafka events more reliably and efficiently.
Better Developer Experience
- Structured Codebase: The refactored codebase adheres to modern best practices, making it easier for developers to understand, maintain, and extend the system. This has led to:
- Faster onboarding of new developers.
- Increased productivity due to a more intuitive development environment.
- Testing becomes super easy with a highly structured and modular codebase. With this new codebase we have achieved more than 60% code coverage which use to be less than 30% in our earlier codebase.
- Clear API Segmentation: With distinct API groups in place, developers can quickly pinpoint issues and deploy targeted fixes without affecting unrelated components.
Scalability and Future-Proofing
- Modular Architecture: The adoption of Domain-Driven Design has positioned us well for future growth. As business requirements evolve, the modular structure allows us to integrate new features with minimal disruption.
Enhanced Monitoring and Observability
Another key benefit of migrating to SpringBoot is its seamless integration with observability tools like New Relic. In our previous Vert.x-based setup, database operations were opaque and challenging to monitor. Now, we can track metrics such as database query times, top DB calls, and overall throughput. This granular visibility empowers us to quickly identify bottlenecks, optimize queries, and maintain a high level of performance across our services.
Lessons Learned and Future Directions
Key Takeaways
- Importance of Incremental Migration: Gradual traffic shifting allowed us to catch and fix issues early, ensuring a smooth transition without any service downtime.
- Investing in Modern Tools: The move to SpringBoot and the adoption of Istio and Redis for routing were critical decisions that paid dividends in terms of performance, reliability, and developer satisfaction.
- Continuous Monitoring: Real-time monitoring and detailed analytics are indispensable. They not only help in immediate issue resolution but also provide insights that guide future improvements.
Future Enhancements
- Enhanced API Security: With the new system in place, we plan to introduce more robust security measures to further protect our APIs and data.
- Deeper Integration with Microservices: As we continue to expand fs-neo, deeper integration with other microservices will enable even more seamless and efficient operations.
- Automation and CI/CD Pipelines: Future plans include refining our continuous integration and deployment processes to reduce manual intervention and further minimize downtime during updates.
Conclusion
The migration from the legacy Fulfilment Service to fs-neo represents a significant milestone in our journey towards a more resilient, efficient, and scalable system. By embracing modern technologies and methodologies—such as SpringBoot, Domain-Driven Design, and advanced routing mechanisms—we were able to perform a seamless, zero-downtime migration that not only improved system performance but also enhanced the overall developer experience.
This transformation not only addresses current challenges but also lays a strong foundation for future growth. As we continue to evolve our technological landscape, fs-neo stands as a testament to our commitment to innovation, quality, and excellence.
We look forward to sharing more insights and updates as we build on this foundation to deliver even greater value to our clients and stakeholders.



