
On demand environments: How we improved developer productivity and experience
At Headout, we live by- move fast, improve fast. As our team grew, testing and validating complex components became a challenge. Here's how we solved it.

At Headout, we follow the mantra “move fast, improve fast”. This allows us to constantly explore and implement improvements in our system. As our team scaled, testing evolving components became tough.
What follows is an insight into how we build a solution to solve this problem.
Growing team; growing problems

For a very long time, our engineering team relied on 2 sandbox environments, which worked perfectly for a team of 20 engineers. As we scaled from 20→50→100 engineers, chaos reigned. Although the number of components being built grew, our overall throughput was a function of 2 sandbox environments, which had no meaningful growth.
Ideas started popping in the air like confetti. Ideas like, having one more copy of the sandbox environment, running and testing the entire stack on local machines, one environment per team and so on. However, none of these were scalable or efficient in the long run—bootstrapping multiple components or managing identical copies came with heavy resource costs and diminishing returns. Clearly, we needed a new approach.
We needed a solution that would fit well into our workflows, scale well, and not cause high operational overhead in the long run.
Introducing On-demand sandbox environments.
The idea was ambitious in its simplicity: replicate our existing sandbox environment with the click of a button, make each copy isolated, identical, and functional, and operational friendly — without draining our resources.
Our key requirements were clear:
- Complete isolation and sandboxing between individual environments
- Fast and easy setup that can be invoked on demand.
- As functional as our basic old school sandbox environment.
- As reliable as we’d like our production environment
All of our applications are containerized, so that was a good start. We did a quick POC with the below setup:
- A basic EKS cluster with basic add-ons and other bootstrapping components.
- New application profile with updated configurations.
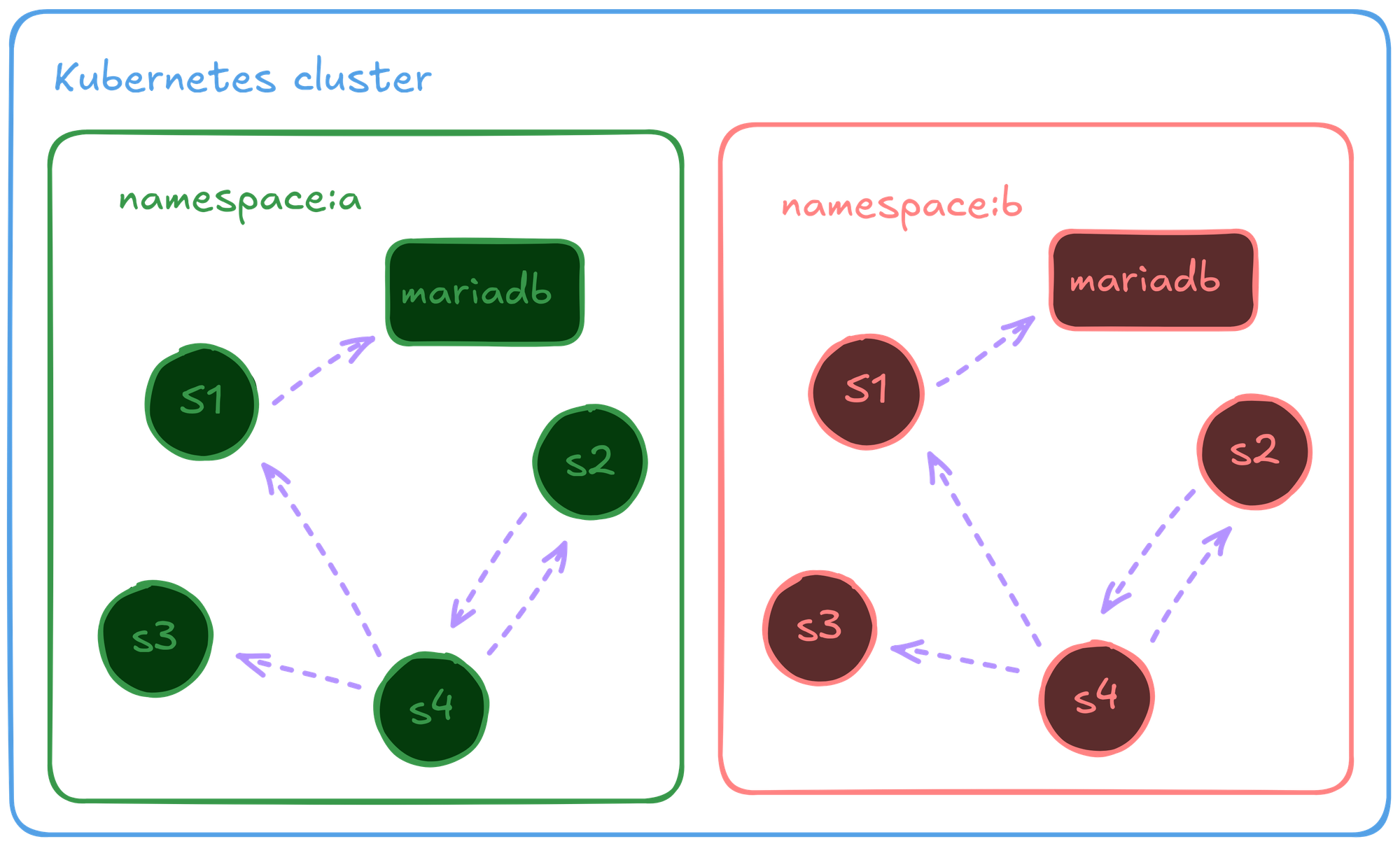
- One Kubernetes namespace for one environment.
- Traffic routed via port forwarding.
- A single containerized db with all necessary schema and seed data.
Why use Kubernetes for such a trivial use case, one might ask ?
For the longest time, all of our services were hosted via AWS elastic beanstalk, which again served us well for a good amount of time. But we needed more flexibility and control over our applications and how they were being hosted and rolled out. Kubernetes was one of the clustering solution which we were considering. This was a good opportunity for us to explore Kubernetes more to see it fits our workflows.
We thought that this setup might just work!
We bootstrapped a small workflow which would automate this entire flow for us, and exposed it to the team so that when needed, they can spawn these isolated environments.
So that’s it ? We did it ?

Well, not quite yet, while our initial POC proved the concept, scaling it further opened Pandora's box revealing more layers of complexity like traffic management, seed data, cost, and "DevEx".
Traffic management
Although port forwarding worked well for some time, it was not efficient enough to run our automated test suits and test all the cases properly.
AWS ALB provided a good start, routing traffic via ingress rules, each environment having one load balancer, and it worked out for some time.
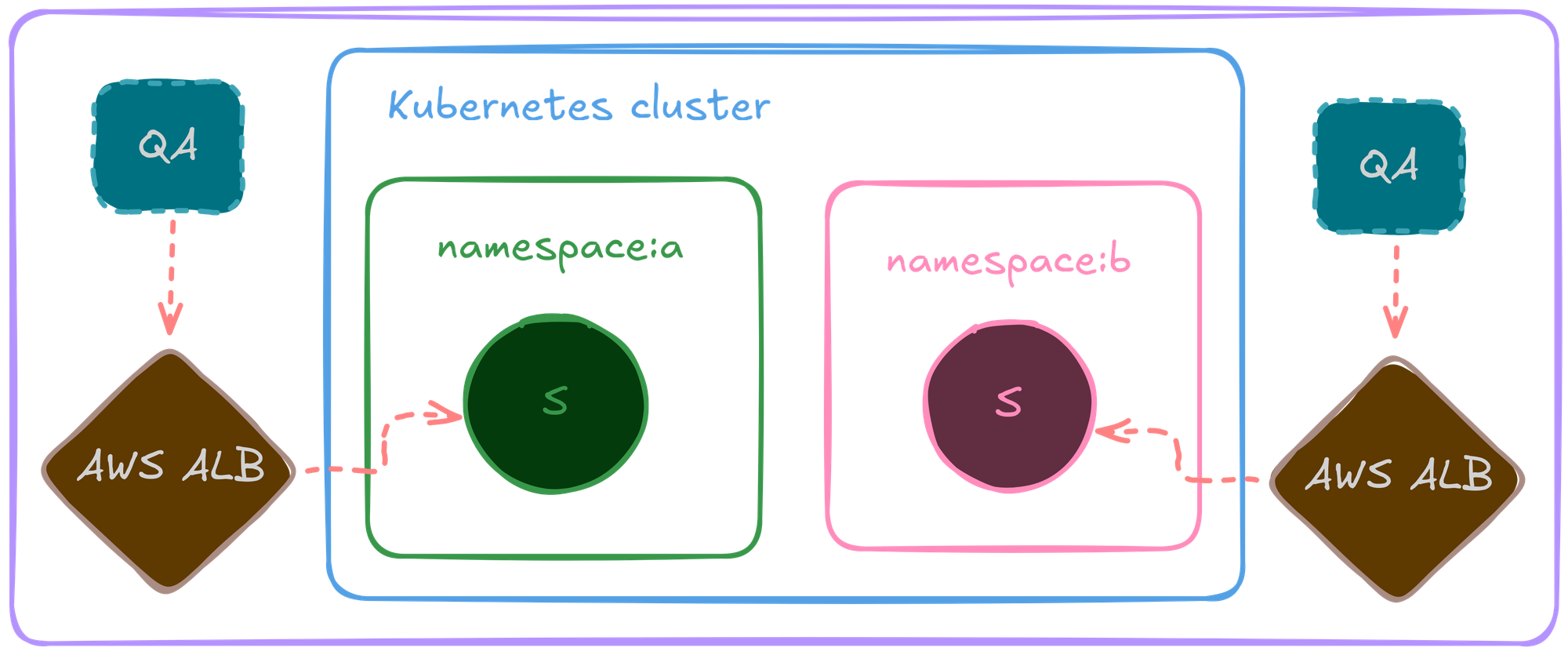
Due to the nature and limitations of AWS ALB, as we scaled, issues like SSL terminations, high cost, operational overhead encouraged us to look for an alternative solution.
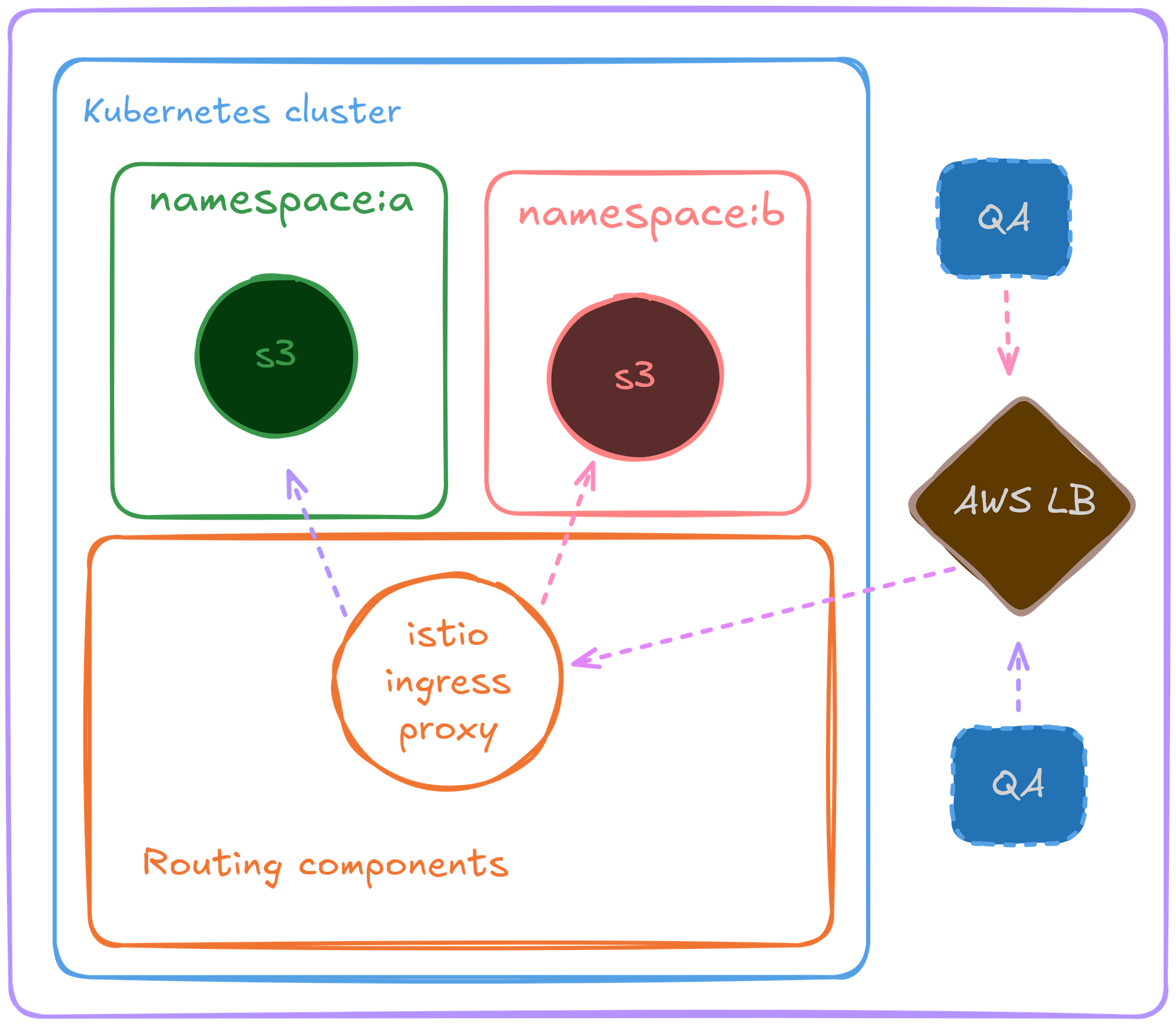
Enter Ingress proxy
We switched to Isito ingress proxy for this, and swapped our ALB with an NLB which was responsible for routing traffic for all the environments via this single NLB.
Along with cert manager’s auto cert creation, and TLS termination on ingress proxy layer, almost all of the issues associated to traffic management were solved.
Test data and db snapshots.
We started off with a simple schema only with very little data, enough to get our apps running. As the usage grew, we realized we needed more data, so we added more data (like, more products, inventory etc etc) :).
As a result, our container image size grew from a few MBs to multiple GBs, which led to painfully slow boot times, error-prone deployments and unreliability.
There was room for improvement…
Volume snapshots to rescue
“Just use EBS volumes” said that one engineer from the corner.
“Of course we should be using stateful volumes for this”, everyone else in the room had a light bulb moment.
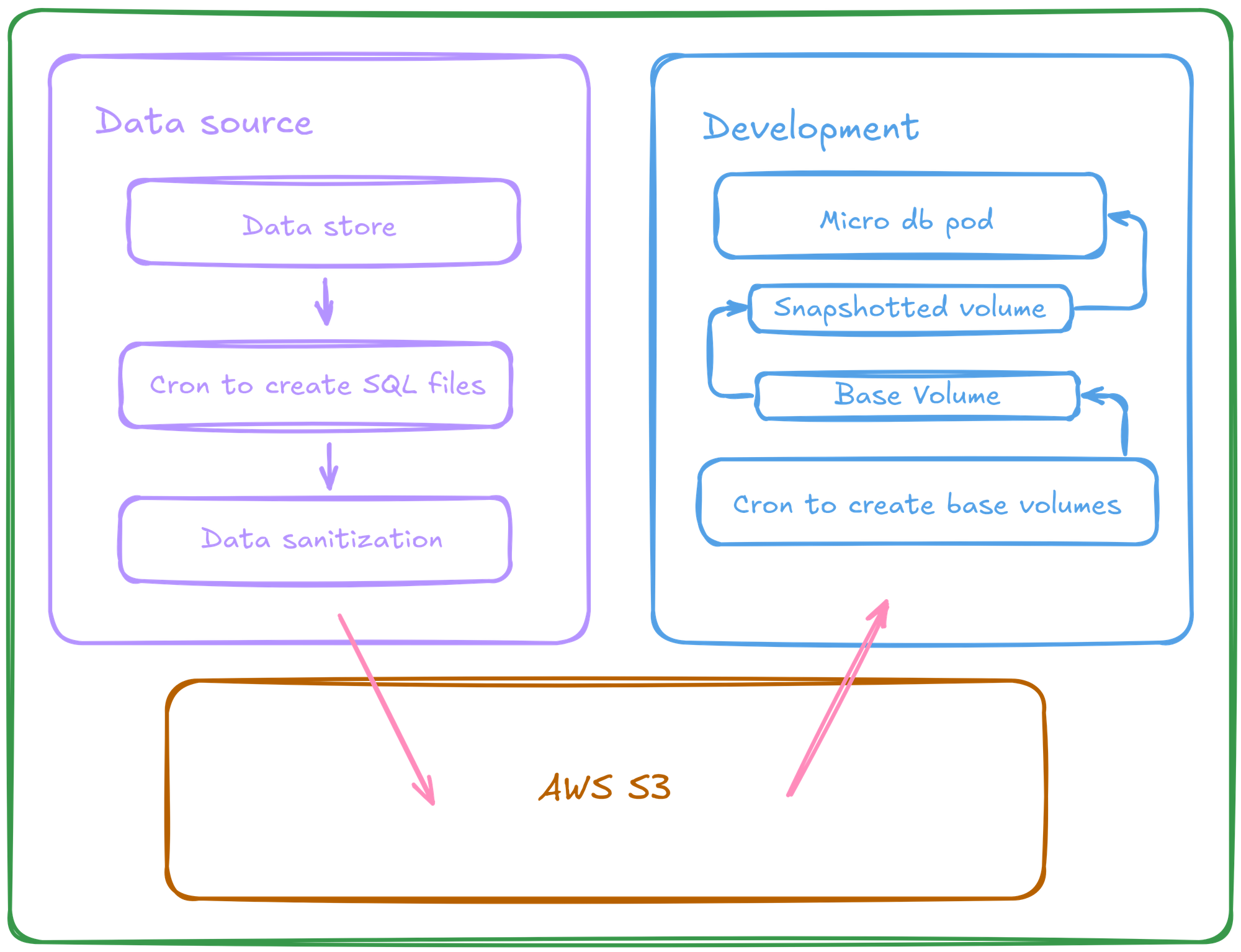
We found kubernetes snapshot controller; volume snapshots offered faster boot-ups and more reliable storage.
The setup looked something like this:
- Periodic creation of testing seed data (post obfuscation / masking PII and other confidential data).
- Seed data was used to boot up a micro-db, and was stored in an EBS volume, which acted as base layer for any new micro-db requirement.
- The rest of the environment would create a volume snapshot of this and use it as the data layer for micro-dbs.
Cost efficiency

Initially, our approach to on-demand environments was a bit...enthusiastic (read: budget-busting, idea was to get the wheels rolling then optimize it). Instances piled up, clusters exploded, and cloud bills soared—peaking at over 25% of our overall cloud cost.
This was mainly due to inefficient node scheduling, orphaned / stale environments, and improper workflows around managing these environments.
Inefficient resource allocations and scheduling
Initially, our cluster was running backed by a Kubernetes cluster autoscaler, with a mixture of burstable / non-burstable, spot / on-demand instances. At first, spot did seem like a good option for this type of workload, it created stability problems for our applications. Even with a mixture of different types of nodes, node usage with cluster autoscaler was not efficient.
We stumbled upon Cast AI, a SaaS solution built just for this. We decided to onboard Cast AI and saw results immediately, our cluster ran with efficiency it had never seen before.
Controlling misuse
Uncle Ben once said, “With great power, comes great responsibility”, and we kind-of ignored the responsibility part.
The project got misused very quickly, causing chaos and operational overhead for everyone. At one point, the cluster had more than 4-6k pods running, which accounted for more than 100 sandbox environment.
This madness had to be controlled for everyone’s sake.
Things we did to improve this
- Daily crons to scale down pods during non-working hours
- Weekly crons to scrape down environments
- Daily crons to delete any orphan resource in the system as a cleanup process.
Knowing when to stop
Although isolation was one of our must-haves, we were careful about creating copies of any particular component, anything that can be shared across, was kept unchanged.
After multiple iterations and improvements, our cloud bills for this project came down by 90% which assured longevity of this solution.
Developer experience
It’s not just about launching apps—it’s about empowering developers with observability, tools, and seamless debugging.
Our toolbox:
- Kiali + Prometheus: Metrics and configs
- ELK stack: Logs
- flyway: Database schema management (extended from existing implementation)
- A web based dashboard for managing these environments and a CLI tool for our terminal enthusiasts.
Since this was a relatively new setup, some of our user flows didn't work properly, these had to be patched later on.
As time went by, we added support for other smaller things like, scaled up environments for load testing, always running environments for UAT (use acceptance testing) for our globally distributed team.
Wrapping up, ~3 years into this.
About three years later, this project stands as a game-changer for how Headout’s engineers ship things. What started as a necessity became a cornerstone of our Kubernetes adoption journey, improving developer efficiency and software reliability.



