Surviving the Whispers of Third-Party Betrayal
One night, our most trusted fraud detection partner went completely silent—no errors, no warnings, just corrupted whispers. What followed was a frantic race to protect our payments system, rethink our dependencies, and build resilience into the shadows.

The Night the Silent Watcher Stumbled
As a payments service provider, we rely on integrations with other companies. One of these, a "silent watcher," was supposed to verify user identities before transactions. The process was meant to be simple:
- Our systems would receive encrypted identity information.
- We would decrypt this information using the "watcher's" tools.
- If our systems couldn't get the information, we'd request it directly from the "watcher."
- The decrypted information would then be used to determine how to prevent fraud.
This worked smoothly until it didn't.
The Incident: When the Silent Watcher Fell Silent
One evening, the "silent watcher" changed its internal workings without any warning. Its systems, its API, stopped functioning correctly. It didn't provide any error messages; it simply went silent or returned corrupted data. This meant we couldn't get valid identity information, which disrupted our fraud detection and blocked transactions.
Imagine our payments system being suddenly shut down by an unseen hand, while we desperately tried to figure out why.
We considered two possibilities:
- A problem with our own systems.
- A problem with the third-party service.
We quickly confirmed it was the latter. This led us to a critical question:
🧐 How do we protect our payments system from failures in third-party services?
The Reality of Whispering Gateways: Illusions vs. Dark Truths
We prefer third-party systems that are well-behaved and predictable, but in reality, integrations with these services are often messy. We expect them to follow certain best practices:
✅ Provide clear error messages (e.g., indicating problems on their end or our end).
✅ Offer a way to check if their service is working.
✅ Announce any changes that might break our integration well in advance.
🚨 The reality: None of this happened.
Instead, the "silent watcher" gave us:
❌ No error messages—only silence or corrupted data.
❌ No way to check its service status.
❌ No warning about the changes that caused the problem.
This made troubleshooting extremely difficult.
The Immediate Dilemma: What Paths Lay Before Us?
We received an alert about the issue, but what could we do?
🛑 Disable fraud analysis? This would leave our system vulnerable to fraud.
⏳ Wait for the third party to fix the problem? This would result in lost revenue from blocked transactions.
🔀 Switch to a backup fraud detection system? This was our best option. We had a backup system which we could use.
This made us realize that we needed to be better prepared for such failures.
Building Resilience: Illuminating the Shadows
To prevent similar problems in the future, we implemented the following:
Monitoring the Silent Watcher's Vitality: Beyond Hope
Since the third party didn't provide a way to check its service status, we created our own:
- Heartbeat Checks: We regularly send requests to the API to detect any issues.
- Response Pattern Analysis: We compare the responses we receive to the expected responses to identify subtle failures.
- Phantom Transactions: We simulate fake transactions to detect problems before they affect real users.
This allows us to proactively detect failures.
How We Implemented It
This section describes the technical details of how we implemented the failover mechanism for the third-party service.
Design Overview
The primary goal was to create a system that could automatically detect failures in the third-party service and switch to a backup system with minimal disruption to the payments flow.
Key Components
- Backup System Integration:
- If the backup system fails, the risk label is set to "NORMAL" to avoid false positives or unnecessary friction for legitimate users.
- This is a deliberate trade-off: in the absence of a working fraud signal, we err on the side of customer experience while ensuring the event is logged and monitored.
- If the backup system’s response time breaches prescribed thresholds, a P0 incident is automatically raised for the on-call team to investigate and restore system health.
- Failover Component: This component determines whether a downtime scenario is detected. It returns a boolean variable:
isDowntimeDetected(true/false). - Feature Flag:
- A local flag,
is_watcher_enabled, stored in Redis, is used to turn the third-party service (silent watcher) ON or OFF. - A global flag,
enabled_watcher, is stored in a properties file and can have three values:"Auto": The Silent Watcher is enabled or disabled based on failover logic."True": The Silent Watcher is always enabled, overriding any failover."False": The Silent Watcher is always disabled, regardless of system health.
- A local flag,
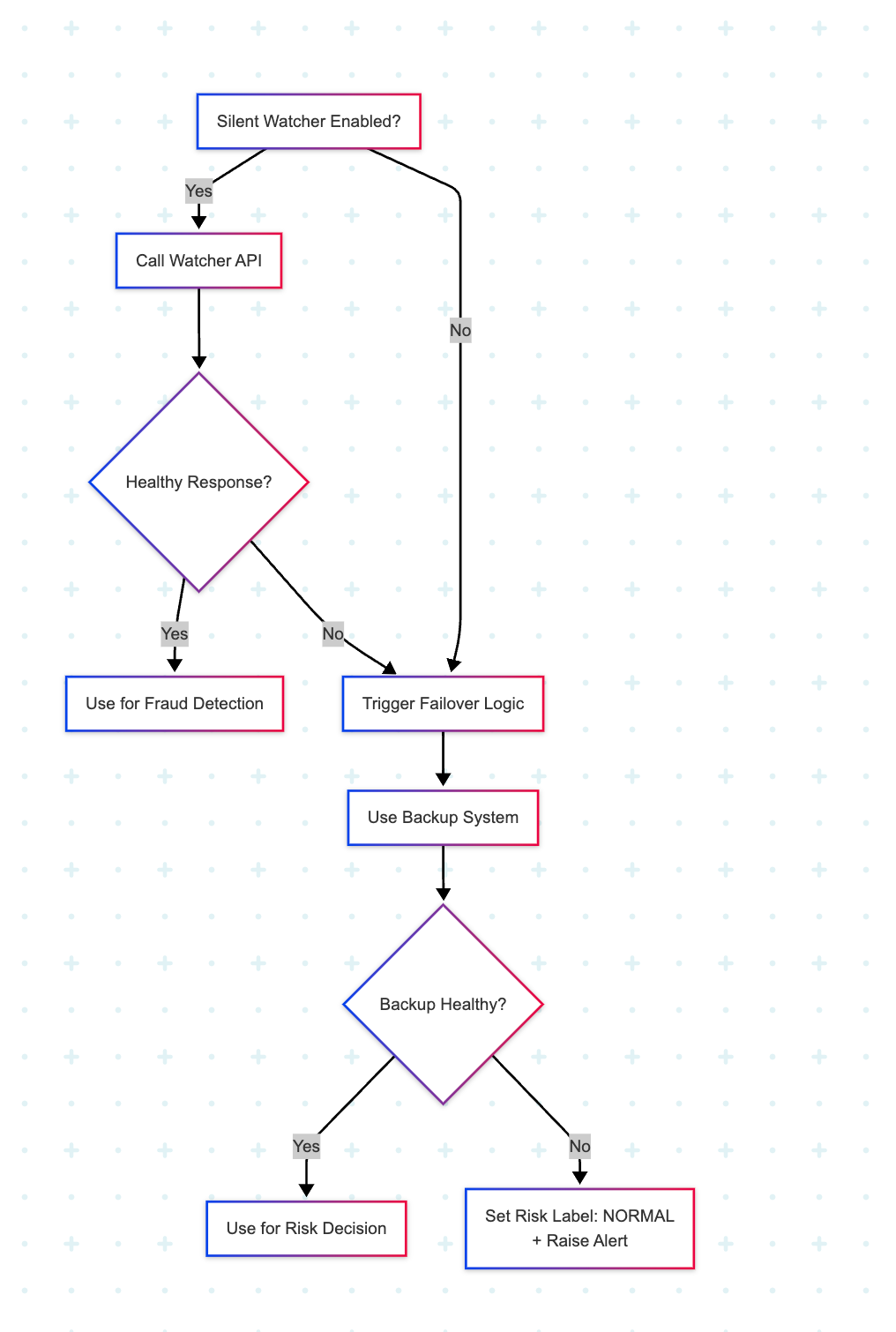
Failover Logic
We use an average error rate over a sliding time window to detect failures.
- Error Rate Calculation:
- Error Rate = (Error Count / Total Hits)
- Constants (Configurable):
- Failover Error Percentage: 95%
- Time Window: 5 minutes
- Window Period: 1 minute
📊 Error Rate Sliding Window (Example)
Consider a sliding window of 5 units, each representing 1 minute.
| Time Window | Error Count | Total Hits | Error Rate |
|---|---|---|---|
| 0–1 min | 0 | 0 | N/A |
| 1–2 min | 0 | 0 | N/A |
| 2–3 min | 2 | 30 | 6.7% |
| 3–4 min | 0 | 30 | 0.0% |
| 4–5 min | 30 | 30 | 100.0% |
In this example, errors begin occurring at 2 minutes and 30 seconds. The error rate is calculated for each 1-minute window. The average error rate is calculated across the 5-minute window.
If the average error rate exceeds the "Failover Error Percentage" (95% in this case), a Redis API is triggered to disable the silent watcher feature.
The values of the windows will be set asynchronously, and the entire failover logic will also run asynchronously.
🛡️ Final Architecture: Watching the Watcher

The Takeaway: When Trust Must Be Verified
The incident with the “silent watcher” was a wake-up call. It reminded us that even the most seemingly reliable systems can fail—and often without warning. But instead of relying solely on trust, we chose to engineer for resilience.
By building layered defenses—heartbeat monitors, phantom transactions, failover logic, and intelligent flags—we turned a fragile dependency into a controllable component. In the world of payments, where every millisecond and every transaction counts, such preparedness isn't just a technical advantage—it's a business imperative.
Failures will happen. But how we prepare, respond, and adapt—that's what defines operational excellence.



