When celery went rogue: Tackling an unexpected 100% CPU usage
A runaway background process sent our CPU soaring. Replacing it with Python threads brought clarity, control, and much-needed calm.

"Why are all the APIs timing out?"
That was the first sign something had gone sideways after deploying our Kafka consumers into production. A quick dive into our metrics revealed the culprit: our worker CPU usage had spiked to a flat 100%. That... wasn’t supposed to happen.
What followed was a deep investigation into how our background systems were behaving under load and how a supposedly idle component was quietly eating up resources.

Setting the scene
In our Django application, we have asynchronous tasks and Kafka producer/consumer workflows. A few months ago, we launched a new event-driven feature requiring additional Kafka consumers:
- Consumer 1: Listening to topics populated by Debezium for real-time database change events.
- Consumer 2: Handling business logics and database operations based on incoming Kafka messages.
Shortly after the rollout, we noticed a disturbing trend: CPU usage on our workers hit the ceiling, and stayed there.
The incident
Here’s how the issue unfolded:
- Following the release, we started receiving bug reports related to API timeouts in the application.
- We began investigating potential causes, suspecting possible bottlenecks.
- A profiling run on the main application showed no abnormalities.
- We then inspected the running containers directly.
- On checking cpu consumption on container level, we found multiple celery threads consuming most of cpu available to the container
- We identified that Celery processes were consuming a disproportionate amount of CPU resources.
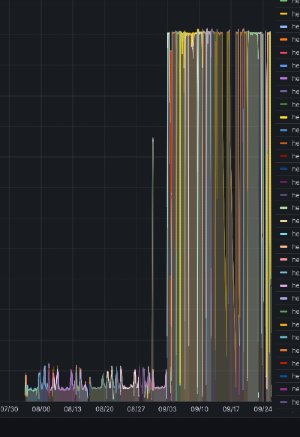
Let’s zoom out for a second
Celery:

A distributed task queue used for executing background tasks asynchronously in Python applications.
Django triggers Celery workers to execute tasks that connect to Kafka topics, continuously poll for new messages, and process them in the background. This setup allows Kafka consumers to run asynchronously outside the main Django request/response cycle, enabling scalable and distributed message handling.
Celery’s task queue model ensures that multiple consumers can operate in parallel across workers, while Django focuses on application logic and user interactions. This approach provides a clean separation between web handling and background message processing, making it easier to manage and scale Kafka-based workflows within a Django project.
Kombu:
Kombu is the messaging library that powers Celery’s communication layer. It abstracts the interaction between Celery and the various message brokers (such as Redis, RabbitMQ, or SQS) that Celery supports. Whenever Celery tasks are sent, received, or acknowledged, Kombu handles the low-level details of message serialisation, broker protocol handling, and connection management.
File Descriptor (FD):
A unique number (handle) that represents an open file or socket within a process.
epoll:
A Linux kernel system call used by Kombu to efficiently poll file descriptors (FDs) for events, crucial for scalability in applications using pull-based message brokers such as Kafka.
Pull-based Brokers:
Workers actively poll or "pull" messages from the broker periodically. The broker doesn't proactively deliver messages.
Example: Kafka, AWS SQS
Push-based Brokers:
The broker actively "pushes" or delivers messages directly to the worker as soon as they arrive. Workers don't need to poll continuously.
Example: RabbitMQ, Redis
🧠 Kombu's Role in Celery
At runtime, Kombu is responsible for:
- Message Broker Abstraction: Kombu allows Celery to work with different message brokers through a unified interface. This means Celery can use RabbitMQ, Redis, Amazon SQS, or other supported brokers without changing its core code.
- Connection Management: Kombu handles connections to message brokers, including connection pooling, automatic reconnection, and error handling.
- Message Serialisation: Kombu provides serialisation, encoding, and compression of message payloads, which Celery uses to convert Python objects to messages that can be sent over the wire.
- Exchange and Queue Management: Kombu implements the concepts of exchanges and queues, which Celery uses to route tasks to workers.
- Producer/Consumer Pattern: Celery uses Kombu's Producer to publish tasks and Consumer to receive tasks, implementing the core task distribution mechanism.
Kombu is a standalone library that can be used independently of Celery, but it was developed by the same team and is a core dependency of Celery. The relationship between Celery and Kombu is similar to that of a web framework and its HTTP library - Celery focuses on distributed task processing while delegating the messaging responsibilities to Kombu.
The technical rabbit hole
Our debugging pointed toward several contributing factors, likely influenced by how the version of Kombu and Celery we were using handled connections and background polling. The behavior we observed aligns with known patterns around resource handling and event loop responsiveness:
- Leaked File Descriptors: Under certain conditions, inactive file descriptors appeared to remain registered in the event loop, potentially causing repeated wakeups.
- Continuous Polling: Kafka's pull-based model, combined with lingering descriptors, resulted in a tight polling loop that kept CPU usage high.
- Silent Epoll Errors: It's possible that some transient epoll errors were not surfaced or acted upon, which could have contributed to the issue.
- Database Contention: High polling frequency increased pressure on the database layer, causing retries and additional processing load.
Our solution: simplifying with python threads
Given Celery's complexity for our Kafka consumers, we opted for simplicity:
- Dropped Celery Completely: We eliminated Celery to reduce overhead and complexity.
- Thread-based Kafka Consumers: Implemented lightweight Python threads to handle Kafka messages directly, significantly reducing CPU usage and complexity.
- Our new setup involves running each Kafka consumer in its own dedicated thread.
- This lightweight threading model avoids the overhead of Celery’s multiprocessing and significantly simplifies our consumer architecture.

Handling thread life cycle:
- A dedicated thread is spawned for each Kafka consumer instance, allowing each consumer to operate independently and concurrently.
- Upon thread initialisation, Kafka consumer configurations, such as bootstrap servers, topic subscriptions, and group identifiers, are set.
- When the thread starts, it immediately enters an infinite loop to continuously poll Kafka for new messages, handling them sequentially.
- Within the polling loop, each incoming Kafka message is decoded, parsed from JSON, and processed by the associated message-handling strategy.
- Error handling mechanisms within the thread ensure robustness by capturing Kafka-related exceptions, logging relevant details, and retrying after a delay if necessary.
- Graceful shutdown of the thread is handled on encountering keyboard interrupts or critical exceptions, ensuring the Kafka consumer is cleanly closed and resources are released properly.

Results: CPU back to baseline

Post-transition metrics:
- Our CPU utilisation returned to original baseline levels, and the application's resilience was restored.
- Reduced code complexity
🚀 Takeaways
- Critically assess if popular frameworks truly match target use case, especially under new workload patterns.
- Always simplify when possible; lighter solutions may significantly outperform complex, distributed architectures for specific tasks.
- Regularly revisit architectural choices, particularly when scaling or introducing new components.
By proactively addressing these root causes, we stabilized our infrastructure significantly. Our experience underscores the importance of continuous architectural evaluations, especially as applications evolve.
References
- Github issues:
- Kombu’s role in Celery: https://github.com/celery/kombu?tab=readme-ov-file
- https://docs.celeryq.dev/projects/kombu/en/stable/introduction.html



